Adding an S3 Incremental Load Job
To add a new S3 incremental load job to the platform, follow these steps:
- Click on the "Configuration Management" menu and select "Table Job Configuration".
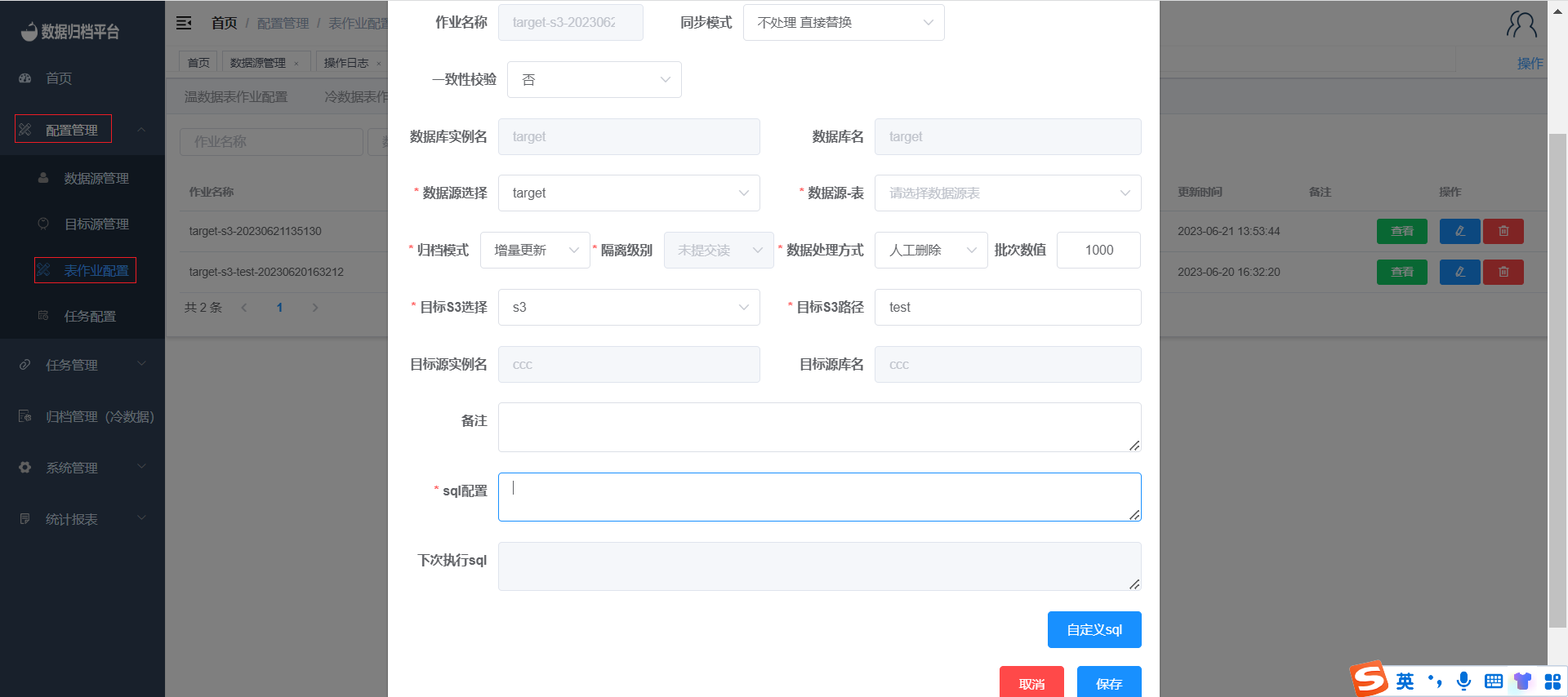
- In the S3 Table Job page, click the blue "Add" button to open the form.
- Choose the data source database table and the target S3 bucket you want to synchronize. Ensure that the source endpoint is MongoDB's Gridfs data as the source for S3 synchronization.
- Select "Incremental Load" as the archive mode.
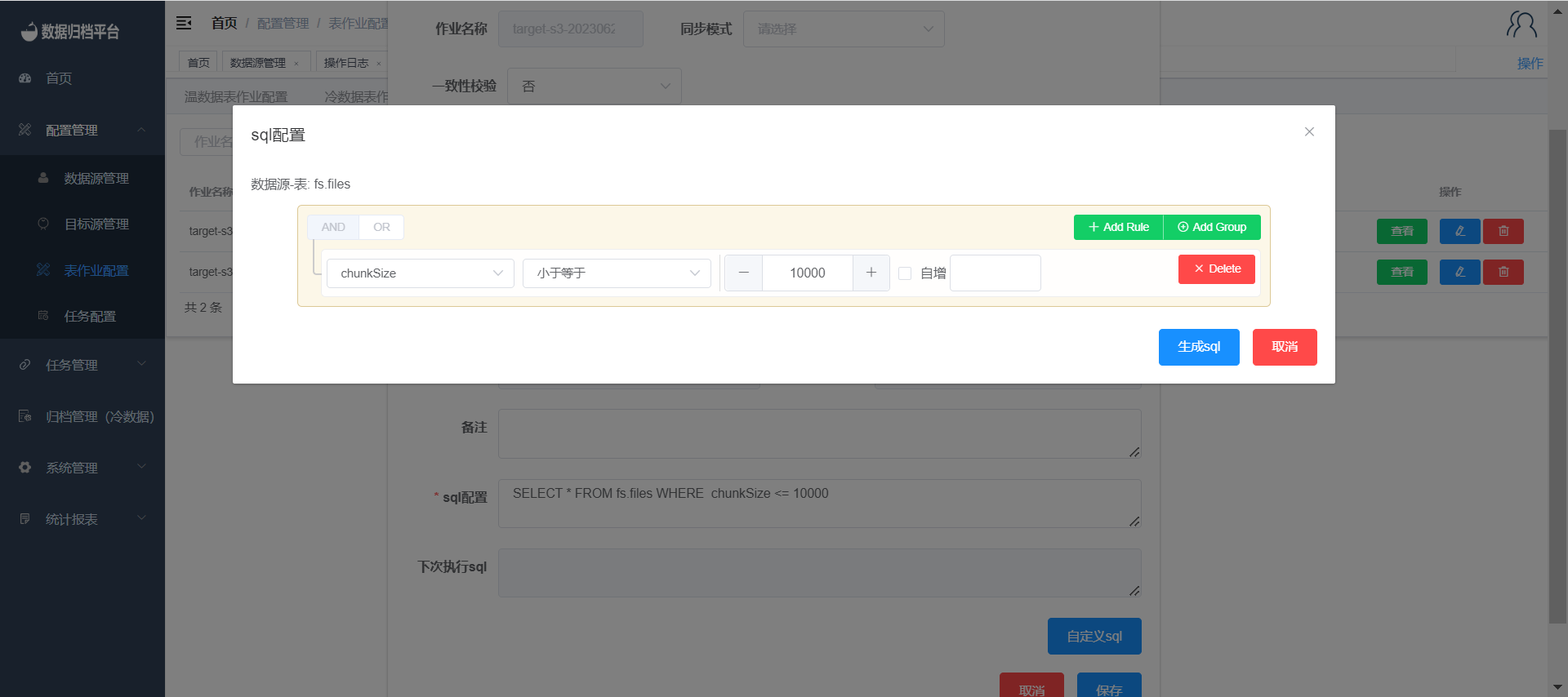
- You'll need to provide SQL configuration since you're choosing incremental mode. Click the blue "Custom SQL" button to open the form for defining the SQL conditions.
- Set up the conditions for the incremental synchronization SQL in the form. After defining the conditions, click "Save" to generate the SQL.
- The table job also includes data consistency verification. If you choose to enable it, you can set the required verification percentage. After the synchronization, the platform will perform data consistency checks on the synchronized data.
- Since S3 has the characteristic that files with the same name will overwrite the existing files, you can choose from synchronization modes like "Replace without Handling", "Replace with Newest Files", or "ID + Filename" mode.
- Choose a data processing method, either manual deletion or automatic deletion, after synchronization. The data source table will be deleted according to your choice after synchronization is completed.
By following these steps, you can create an S3 incremental load job that synchronizes data from a MongoDB Gridfs data source to a target S3 bucket using incremental synchronization based on defined SQL conditions. This allows for efficient and selective data synchronization within the Whaleal Data platform.